Python is a great language for the on-demand style of Lambda, where startup time matters. In terms of execution speed, there are better choices available. Where computational performance matters one improvement is to use Pypy, the Python interpreter with a JIT compiler. It can execute the same code much faster. There is just a slight penalty in startup time compared to CPython.
I was curious how Python and Pypy would compare on AWS Lambda. As Amazon announced recently, it is now possible to provide your own Runtime for Lambdas.
Creating a Custom AWS Lambda Runtime
Before you can start with creating your own runtime you should have a simple Lambda function. I recommend you start by creating a serverless application. This way you not only get a plain Lambda but also an API Gateway and Cloudwatch logs set up. And it is much quicker to edit code, iterate and put it to version control.
Creating a new runtime is based on a shell script you have to provide. This script will do initialization work, call an interface for requesting the next task/incoming request, dispatch it to whatever runtime you are providing and respond to another interface with either a success or an error message.
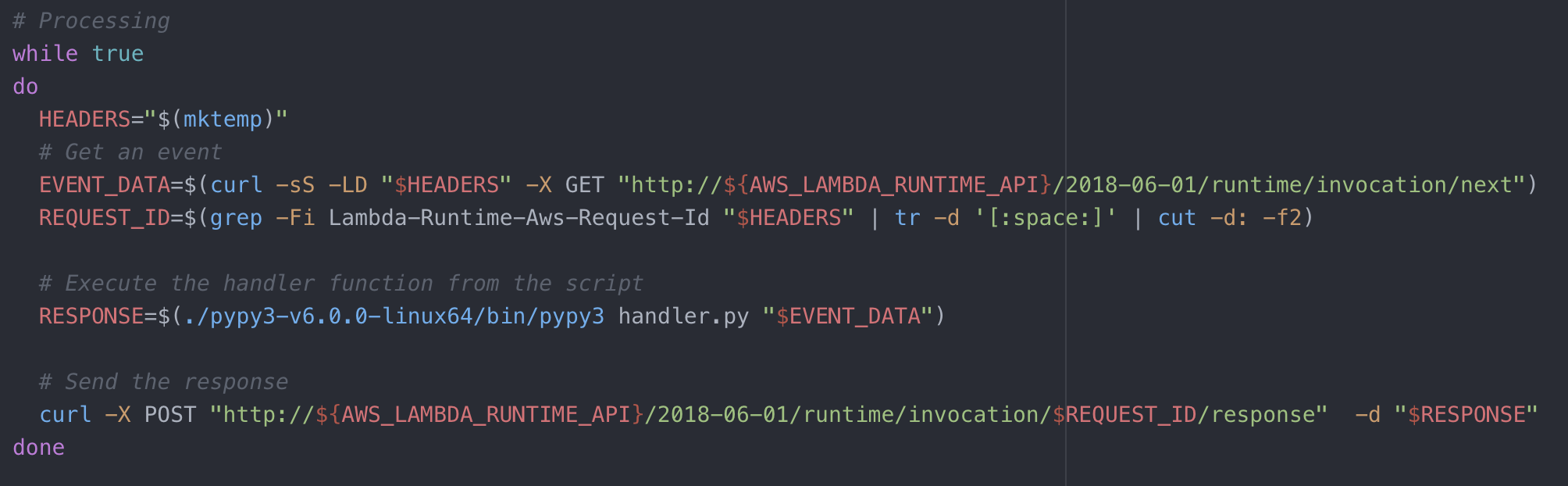
Starting from the example is easy. You can quickly set up a test project using serverless that will execute the example bootstrap code. The example runs in an endless loop, working on one task in each iteration. AWS must be starting/killing this loop based on how many tasks are waiting for execution and probably some other factors.
Pypy does not run out of the box. The interpreter has to work on Amazons Linux environment. Unfortunately, downloading a compiled binary didn’t just work for me. And I couldn’t find a version specifically for the Amazon Linux. The problem is that a libbz2 library was not available. In fact, it is available in the environment but Pypy does not find it. The recommended solution to create a symbolic link to the library is also not an option, because the environment is read-only (except for /tmp/). To not spend too much time on this I fired up an EC2 instance with the Amazon default image and copied that library next to the Pypy interpreter into my package.
To create a first “Hello World from Pypy” application running you need to call Pypy from within the shell script and send the response back to the Runtime Interface. There is no error handling yet and starting a new Pypy process on every request is far from optimal, but this is already a working solution.
A better way is to move the processing loop from shell script into Pypy. This way there already is a running process, all imports have been done and if parts of the code use initializers or caching this state will be kept for the next request. The bootstrap script looks a lot simpler now:
![]()
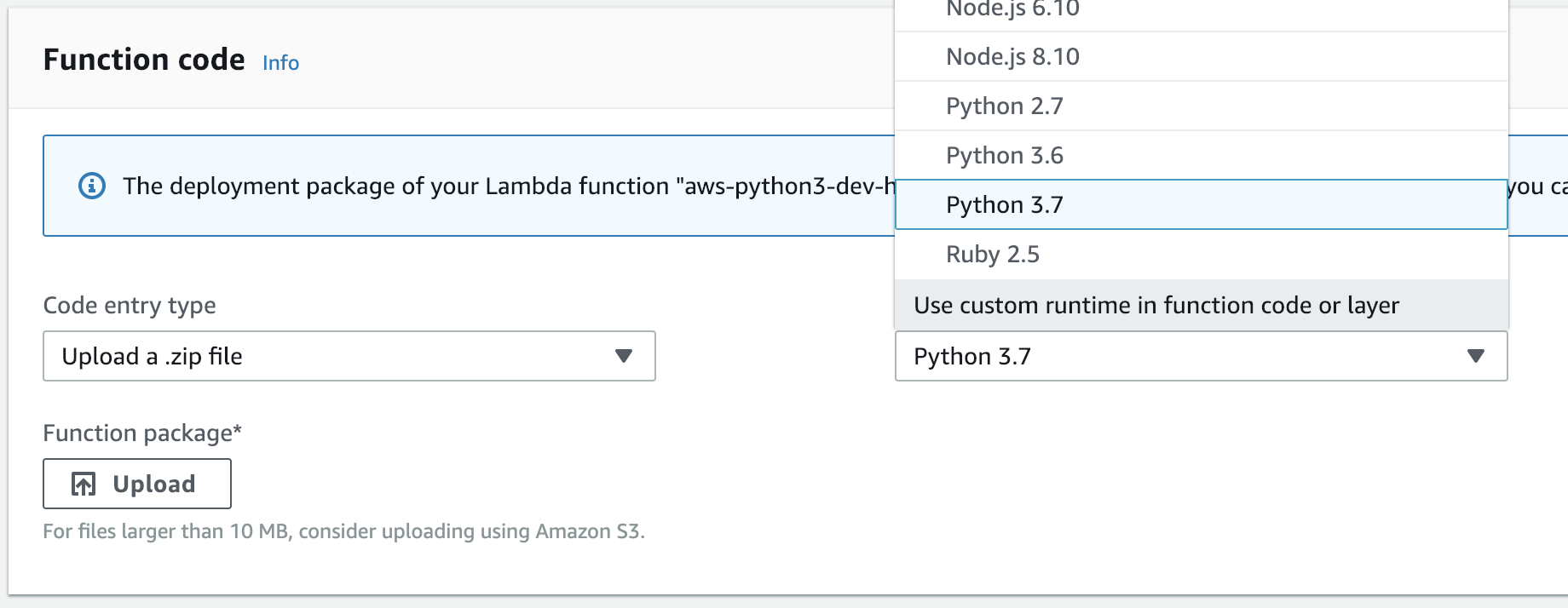
The logic is now located in Python code and run by Pypy. With the custom runtime code in place, we can switch between a standard Python3.7 runtime and our own in the AWS Lambda web interface:
Comparing Pypy and Python3.7
So how does the simple Pypy runtime compare to the default Python3.7 implementation? Let’s create an example where the Lambda has to use its CPU. I wrote a simple one-liner to calculate prime numbers from 2 to 200000:
![]()
For sure there are better algorithms to do the same thing, but it serves the purpose well. Calculating the prime numbers takes considerably longer with CPython than with Pypy. On my machine, it takes around 1 second with Pypy and 3 seconds with CPython.
In an AWS Lambda environment, both runtimes are executing the same handler.py and calculate prime numbers. This is how long they take to run the code:
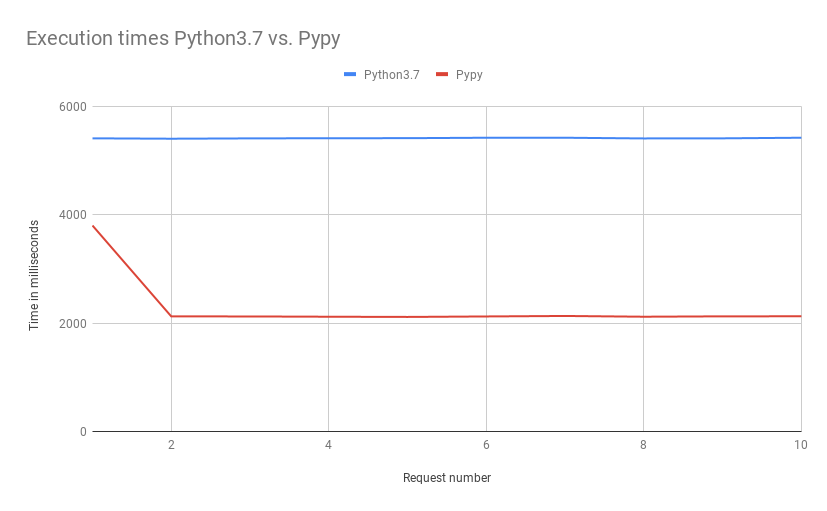
Calculating the primes takes more than 5 seconds when executed with python3.7 but only slightly above 2 seconds with Pypy. We have found a case where Pypy is a lot better than CPython. This was my hope when starting to build the runtime.
But, as you can see in the first request, the Pypy runtime takes a long time to initialize. This is logged in CloudWatch as “Init Duration: 1641.69 ms”. In this test scenario, it does not matter because a request takes many seconds to finish. With its better computational performance, the Pypy runtime still comes in first. In a more typical scenario, this Init Duration will be much more important. And this brings us to the downsides of this approach.
Downsides of the Custom Runtime
The initialization phase takes way too long. It is not visible what exactly happens during that time. But the bulky size of the code package will most likely be part of it.
Let’s rerun the same test as before but without the heavy calculation and ignore the Init Duration:
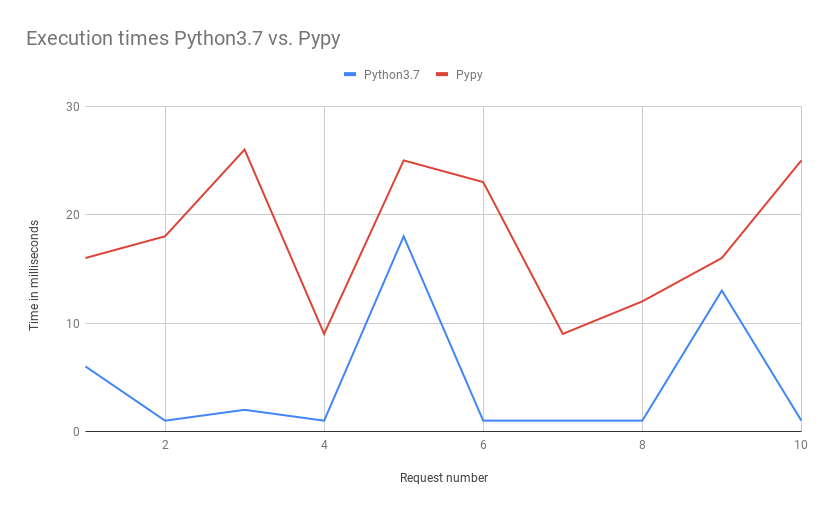
The execution time for a “Hello World” application is higher than with Python. I don’t understand why this is the case. Monitoring Pypy runtime_interface gives me sub-millisecond times for what my code executes. Still, the Lambda execution Duration is reported to be somewhere between 10 and 30 ms. In contrast, executing the function with Python3.7 gives Durations close to 1 ms with only a few spikes. This should be more or less equal. There either is a problem in my implementation or in how AWS handles a Custom Runtime. If you have an idea what goes wrong here please add a comment. In any way, this diagram is much closer to real-world usage. And Python is faster here.
Also, the deployment package is big. Nearly 30 MB are uploaded to S3, even though there is hardly any function code inside. For many cases, this is going to be a showstopper. I believe the package size can still be reduced by specifying in more detail which Pypy files are necessary. If Amazon ever considers this as a default choice it would solve the issue, because then you would not have to upload the interpreter within your package.
Wrap-up
Running Pypy on AWS Lambda as a custom runtime is possible and not very complicated. There is a clear advantage over CPython when it comes to long-running computations. Packaging the whole interpreter bloats up your Lambda package and increases your initial startup time. Typically, being lightweight and having a quick startup is more important than raw computational speed. Therefore, I can only recommend this approach for exceptional cases.
If Amazon decides to provide Pypy as a default Runtime, this could be different. You would not have to bundle the interpreter and the startup time might become a lot better than now while the computational advantage of Pypy will still be there.
You can find all the code in my Github repository.
Related Posts
Building a very easy text classifier in python
Some of the developers at match2blue are creating a text-interest-matcher. Leaving buzzword bingo aside, that means the software calculates whether a text is interesting based on users' interests. So basically you, as a user, have…

Paragliding data gems
Paragliding is my beloved hobby and besides offering stunning views and perfect days outside, it also provides a huge amount of flight data to process and play around with. Sites like xc.dhv.de, XContest contain millions…

Calculate wind from thermals
This post is a followup to the last one about Paragliding data gems. We have collected lots of flights and their GPS location data. From this, several million thermals were extracted and shown on a…